
- Forums
- Product Forums
- General Purpose MicrocontrollersGeneral Purpose Microcontrollers
- i.MX Forumsi.MX Forums
- QorIQ Processing PlatformsQorIQ Processing Platforms
- Identification and SecurityIdentification and Security
- Power ManagementPower Management
- Wireless ConnectivityWireless Connectivity
- RFID / NFCRFID / NFC
- Advanced AnalogAdvanced Analog
- Neural Processing UnitsNeural Processing Units
- MCX Microcontrollers
- S32G
- S32K
- S32V
- MPC5xxx
- Other NXP Products
- S12 / MagniV Microcontrollers
- Powertrain and Electrification Analog Drivers
- Sensors
- Vybrid Processors
- Digital Signal Controllers
- 8-bit Microcontrollers
- ColdFire/68K Microcontrollers and Processors
- PowerQUICC Processors
- OSBDM and TBDML
- S32M
- S32Z/E
-
- Solution Forums
- Software Forums
- MCUXpresso Software and ToolsMCUXpresso Software and Tools
- CodeWarriorCodeWarrior
- MQX Software SolutionsMQX Software Solutions
- Model-Based Design Toolbox (MBDT)Model-Based Design Toolbox (MBDT)
- FreeMASTER
- eIQ Machine Learning Software
- Embedded Software and Tools Clinic
- S32 SDK
- S32 Design Studio
- GUI Guider
- Zephyr Project
- Voice Technology
- Application Software Packs
- Secure Provisioning SDK (SPSDK)
- Processor Expert Software
- Generative AI & LLMs
-
- Topics
- Mobile Robotics - Drones and RoversMobile Robotics - Drones and Rovers
- NXP Training ContentNXP Training Content
- University ProgramsUniversity Programs
- Rapid IoT
- NXP Designs
- SafeAssure-Community
- OSS Security & Maintenance
- Using Our Community
-
- Cloud Lab Forums
-
- Knowledge Bases
- ARM Microcontrollers
- i.MX Processors
- Identification and Security
- Model-Based Design Toolbox (MBDT)
- QorIQ Processing Platforms
- S32 Automotive Processing Platform
- Wireless Connectivity
- CodeWarrior
- MCUXpresso Suite of Software and Tools
- MQX Software Solutions
- RFID / NFC
- Advanced Analog
- Neural Processing Units
-
- NXP Tech Blogs
- Home
- :
- MQX Software Solutions
- :
- MQX Software Solutions
- :
- MQX 4.1 SPI with interrupt problem?
MQX 4.1 SPI with interrupt problem?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
MQX 4.1 SPI with interrupt problem?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello. I'm using MQX 4.1 with K20_120 microcontroller. It's clear that DMA usage in SPI drivers is not stable, so I decide to switch driver to interrupt driven transfers.
In my project I have ADS1298 connected to SPI0 port. This chip asserts a pin to event the microcontroller regularly on each 1ms and I need to read the 27 bytes shortly after the event (before next 1ms event comes). The baud rate of the SPI is 1Mhz. At the begging, all is working fine, but after a given time, all the communication goes out of synchronization.
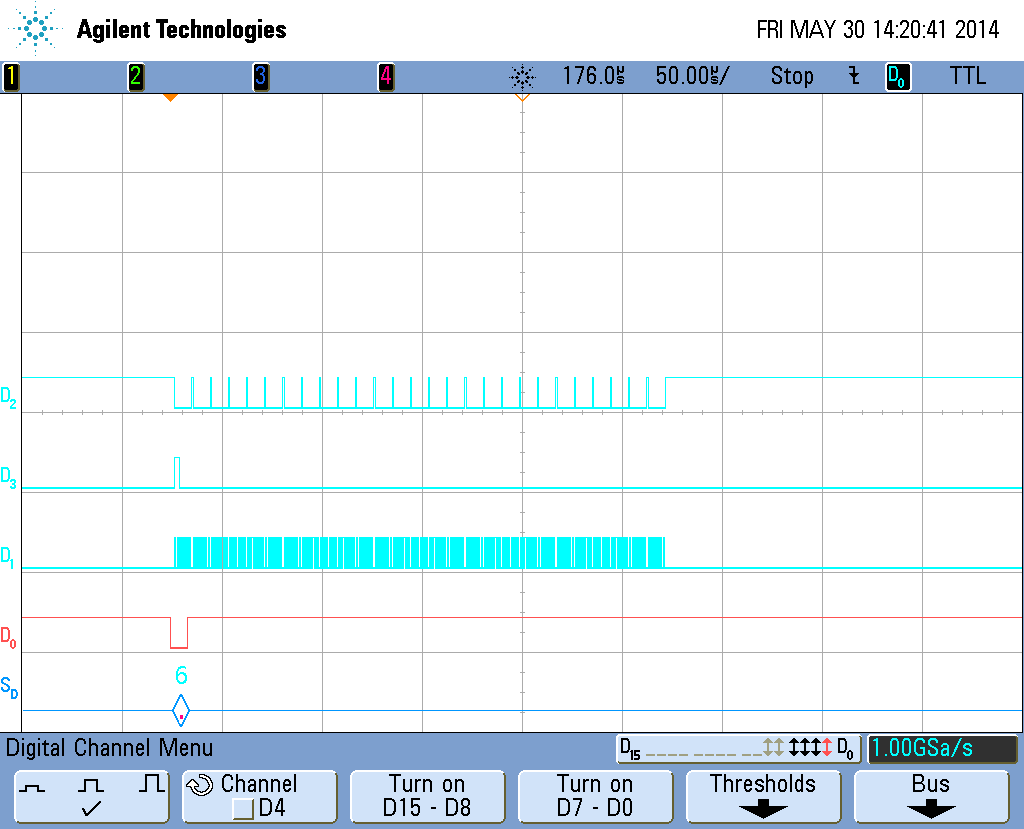
See scope_1.png : D0 - nCS, D1 - SCLK, D2 - MISO, D3 - MOSI. I'm using regular _io_read() access of the driver. The CS goes active from the driver management and returns inactive by me with _io_flush() after finishing of _io_read().
Note that, the CS signal returns to inactive state very shortly after start of the frame. The data transfer is not interrupted as you see - there is 216 clocks which are exactly 27 bytes. But the CS signal brakes the communication. In fact the CS is returned inactive by my code, because _io_read() function finishes. It reports 27 bytes read, even it returns before the first byte is finished.
After 2 days digging in spi_dspi.c file I have found the following: There is a semaphore which is used to synchronize the state machine of the driver. The logic is as follow - first write 4 bytes in SPI TX fifo, enable RX interrupt and sleep on semaphore. The SPI RX interrupt transfers the rest of the frame and at the end it disables SPI interrupts and posts a semaphore to wakeup the thread when communication ends. All this works fine but for a short time. At some moment, the nCS signals becomes crazy and returns inactive before frame end. I found that after a given time, the sleep on semaphore not works, and this is because semaphore is already there ( there is a semaphore posted in queue just before _lwsem_post(&dspi_info_ptr->EVENT_IO_FINISHED) ); So the thread do not sleeps and get out of the _io_read() function after which I'm calling _io_flush() and which inactivates CS. The ISR continues to work so the frame is transmitted in parallel with my thread operation.
So after additional 2 days behind the monitor, I have tried to catch the problem with pin toggling. So I have put a simple ON/OFF on a test pins on semaphore post and semaphore wait in spi_dspi.c file . See scope_2.png - this is at the time when all is working.
D4 - set before _lwsem_wait() call / cleared after _lwsem_wait() finished.
D5 - set before _lwsem_post() call / cleared after _lwsem_post() finished.
All seems normal - the thread goes to sleep for the entire transfer (D4 high)), the semaphore is posted at the end of the transfer ( peak on D5) ,after the thread weak ups (D4 goes low). But look on next scope_3.png. This is the "last" frame before the communication goes bad. There are two short spikes on D5. This means that at the end of transfer two post of semaphore are made in some reason in the ISR.
When I have checked the timing of the scope, I have found that these spikes are very close each to other, seems that in some reason the interrupt is serviced twice. Normally this should not be possible, because after last byte, the SPI_RSER register is cleared. So to check this I have included the following test code in _dspi_isr() function ( just at the begging):
SR_value = dspi_ptr->SR;
RSER_value = dspi_ptr->RSER;
if( RSER_value == 0 ){
_ASM_NOP();
}
SR_value and RSER_value are global variables declared for test. Normally _ASM_NOP() should never happens - this means that we are in ISR but the interrupts are disabled, so normally we cannot be there. But surprise - when I put a breakpoint at this point - after a given time it stops there. I have checked the RSER register - it's 0! If I continue - future communication drops down, since two semaphores are posted, and thread no more can go in wait for semaphore state. The efect continues, after a given time the debugger stops on NOP again and again. So the semaphore increases more and more, and in fact wait for semaphore never more sleeps.
So the question is how we can enter in _dspi_isr() function with cleared RSER register ??? Is it a bug in the silicon? Or something happens with int_kernel_isr() function which wraps the spi_dspi interrupt function? The problem is that this kernel interrupt function is written in assembler so it's really difficult to check what happens there... for the moment, I don't have a time to dig inside it.
Now I have put a "return" at the place of _ASM_NOP(). So I don't service interrupt if it's disabled by RSER - all works fine now. But it's not a solution, it's a hiding of the problem.
I'm attaching the pictures as follow:
1 - the bad communication frame (CS is not correct)
2 - normal frame with two pins toggles on semaphore post/wait.
3 - last frame before communication goes down (with pin toggling again).
I'm sending you the modified dspi driver function, which I'm using for tests. The changes are marked with //TM.
I will appreciate any help or ideas from peoples which are known with MQX structure, since I'm pressed in the project scheduling!
Original Attachment has been moved to: spi_dspi.c.zip
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I know this topic is quite old, however we were experiencing this same issue that would ultimately manifest itself as a complete SPI transfer lockup after approximately 60 days of continuous operation. I was able to resolve the issue and locate the root cause issue.
SHORT version:
The driver is not checking the state of the SPI module when writing to the CTAR, RSER and MCR registers. Specifically, the SPI module must be in the "Stopped" state before writing to them. This requirement was specifically called out in the NXP documentation.
I've attached an updated source file that fixes the issue.
FYI, I believe this issue is still present even in the latest KSDK..
LONG version:
Issue:
On a Kinetis K61 processor using MQX OS SPI drivers, SPI receive ISR events were occurring despite all indicators in the SPI controller module ( FIFO counters, interrupt enabled states, etc ) that an ISR should NOT be occurring. These unexpected ISR events are resulting in an erroneous posting of the lightweight semaphore ( lwsem , "EVENT_IO_FINISHED" ) used to coordinate between SPI transmission ( TX ) and SPI receive ( RX )events. The erroneous lwsem posting results in continuous
fall-through in _dspi_tx_rx() where the function waits for the lwsem after a TX. A posting of the lwsem should indicate that all RX events have completed.
Eventually the erroneous postings will accumulate and cause the lwsem count to rollover. On a lwsem post , the lwsem is incremented by one count under the MQX OS lwsem handler. The handler does not check for a rollover condition before incrementing the count.** The lwsem count value is a signed 32-bit container ( -2,147,483,648 to 2,147,483,647 ).
A rollover into a negative value will result in an indefinite lockup of the lwsem. Depending on the spi transfer intervals, this could take days or months before the lockup occurs.
NOTE: For testing purposes, temporarily changing lwsem VALUE type to int16_t will significantly reduce this interval.
** Although there is an argument to be made that a semaphore count value should not be allowed to rollover ( it depends on the design philosophy of the OS ), that is not the root cause of the issue.
Root Cause:
A review of the low level driver against NXP documentation indicates that portions of the driver code was not verifying that the SPI module was in "Stopped" state before writing to CTAR, RSER and MCR registers.
According to NXP K61 documentation (1) :
Section 53.3.1 (SPIx_MCR):
"Contains bits to configure various attributes associated with the module operations. The
HALT and MDIS bits can be changed at any time, but the effect takes place only on the
next frame boundary. Only the HALT and MDIS bits in the MCR can be changed, while
the module is in the Running state."
Section 53.3.3 (SPIx_CTARn):
"CTAR registers are used to define different transfer attributes. Do not write to the CTAR
registers while the module is in the Running state."
Section 53.3.6 (SPIx_RSER):
"RSER controls DMA and interrupt requests. Do not write to the RSER while the module
is in the Running state."
Discussion:
Section 53.4.1 "Start and Stop of module transfers" details the "Stopped" and "Running" states:
"The TXRXS bit in the SR indicates the state of module. The bit is set if the module is in
Running state.
The module starts or transitions to Running when all of the following conditions are true:
* SR[EOQF] bit is clear
* MCU is not in the Debug mode or the MCR[FRZ] bit is clear
* MCR[HALT] bit is clear
The module stops or transitions from Running to Stopped after the current frame when
any one of the following conditions exist:
* SR[EOQF] bit is set
* MCU in the Debug mode and the MCR[FRZ] bit is set
* MCR[HALT] bit is set
State transitions from Running to Stopped occur on the next frame boundary if a transfer
is in progress, or immediately if no transfers are in progress."
This SPI driver does not utilize / control the SR[EOQF] bit or associated RSER EOQF control
and we will not be employing the MCR[FRZ] bit under normal operation.
We can use the MCU[HALT] bit to control the Stopped / Running states.
Resolution:
Create code to halt (as needed ) SPI module, putting module into "Stopped" state
Create code to handle returning into the "Running" state if we stopped it
NOTE: Changes are based on MQX OS v4.1 BSP driver
References:
1. NXP K61P144M150SF3RM.pdf K61 Sub-Family Reference Manual, Rev. 3 , November 2014
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello
Many thanks to Tsvetan Mudrov to help us for detection and for workaround proposed.
I detected the same phenomena using K64 and MQX SPI driver.
I used a similar workaround and it work well.
In my change I just read SPI_SREG at the beginning of DSPI_DRV_MasterIRQHandler function (I don’t use DSPI_DRV_IRQHandler function because my SPI is always master)
if ( SPI_RD_RSER(base) == 0 ) return;
I can give my contribute reporting my experience about this problem:
In firsts tests the phenomena never occurred.
Then I unsychronized the task that manage the SPI with tick timer (another hw timer executes a post to semaphore to end the task waiting). After this change the phenomena starts to occur.
I added also a counter controlled by <if> condition to detect the phenomena. Without workaround (return instruction) the task stops at the first count. With workaround the counter increases and task never stops.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Seems like I have same problem for my SPI driver of MQX4.1.1. It is reproducible on my board with 1M bps baudrate , 8b frame size, big endian, clock mode 0.
Disabling DSPI_ATTR_USE_ISR seems to help. Another thing I noticed is that the transaction time measured from slave device IRQ assertion time is 100us shorter than the case with DSPI_ATTR_USE_ISR enabled.
In attached pictures, ch1 is IRQ asserted by slave device while ch2 and ch3 are MISO and MOSI respectively. "read_good" shows a successful reading from device while the "bad_read" shows a failure of device reading.


{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had the same problem as well a while back and never posted up here. Never got around to trying to work on a fix. Just implemented a workaround. Many thanks to tsvetanmudrov for properly documenting the issue. You saved us many hours of digging around ourselves.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello. Sorry for the late answer on this thread. In my case the situation is the following:
1. I have not received any reasonable help for this problem from Freescale support.
2. My "workaround" seems to work well in my case. It masks effectively the problem, but be care - it's not a real solution. We are using this solution in prototype device.
3. I have other issues with Kinetis micros and MQX. In my opinon this is well written OS, but it's written for older series of micros. Now Freescale try to adapt it to Kinetis. So on higher levels it works pretty well, but there are a lot of bugs and "features" on the driver level which makes the usability under question at all.
I still don't have good support for such a problems by Freescale. It's sure we are not in automotive or communication bisness, we are a realtively small client. Maybe this is the reason for lack of good support. So we decide to switch the manufacturer, our new devices are based on concurrent Cortex M4F from ST. We have changed the OS also. This costs us aditional 15 weeks of development, but we are sure this was the right solution. The level of support there is one step higher. The comunity of users is also much bigger and active to help when needed.
It's a sadly case, because I have a good expirience with older Freescale micros. But seems it will not be the case in the future.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TM, did you get a solution to this problem? I'm having a very similar problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've been dealing with SPI problems in MQX. In the end, I used the MQX 4.1 SPI drivers when I'm doing SPI master. I haven't had the problems you're talking about. For SPI Slave I used the Processor Expert SPI driver, which is not DMA based. I did find another SPI driver here: https://github.com/laswick/kinetis/blob/master/phase2_embedded_c/spi.c but I haven't tried it yet. It looks very clean and it's completely agnostic of MQX, which is probably the right solution.