
- Forums
- Product Forums
- General Purpose MicrocontrollersGeneral Purpose Microcontrollers
- i.MX Forumsi.MX Forums
- QorIQ Processing PlatformsQorIQ Processing Platforms
- Identification and SecurityIdentification and Security
- Power ManagementPower Management
- Wireless ConnectivityWireless Connectivity
- RFID / NFCRFID / NFC
- MCX Microcontrollers
- S32G
- S32K
- S32V
- MPC5xxx
- Other NXP Products
- S12 / MagniV Microcontrollers
- Powertrain and Electrification Analog Drivers
- Sensors
- Vybrid Processors
- Digital Signal Controllers
- 8-bit Microcontrollers
- ColdFire/68K Microcontrollers and Processors
- PowerQUICC Processors
- OSBDM and TBDML
- S32M
-
- Solution Forums
- Software Forums
- MCUXpresso Software and ToolsMCUXpresso Software and Tools
- CodeWarriorCodeWarrior
- MQX Software SolutionsMQX Software Solutions
- Model-Based Design Toolbox (MBDT)Model-Based Design Toolbox (MBDT)
- FreeMASTER
- eIQ Machine Learning Software
- Embedded Software and Tools Clinic
- S32 SDK
- S32 Design Studio
- GUI Guider
- Zephyr Project
- Voice Technology
- Application Software Packs
- Secure Provisioning SDK (SPSDK)
- Processor Expert Software
-
- Topics
- Mobile Robotics - Drones and RoversMobile Robotics - Drones and Rovers
- NXP Training ContentNXP Training Content
- University ProgramsUniversity Programs
- Rapid IoT
- NXP Designs
- SafeAssure-Community
- OSS Security & Maintenance
- Using Our Community
-
- Cloud Lab Forums
-
- Knowledge Bases
- ARM Microcontrollers
- i.MX Processors
- Identification and Security
- Model-Based Design Toolbox (MBDT)
- QorIQ Processing Platforms
- S32 Automotive Processing Platform
- Wireless Connectivity
- CodeWarrior
- MCUXpresso Suite of Software and Tools
- MQX Software Solutions
- RFID / NFC
-
- Home
- :
- Product Forums
- :
- MPC5xxx
- :
- Re: SYS_RAM_UNCERR_ADDR record a flash address.
SYS_RAM_UNCERR_ADDR record a flash address.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
SYS_RAM_UNCERR_ADDR record a flash address.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

Hi all,
Our software running on the MPC5777M, our software utilize the AUTOSAR platform which the Autosar OS running. Our software normally run flawlessly, however, in some very rare circumstance that I don't know what it is, the OS report a MEMORY protection issue, indicate that our software access the illegal memory. We have traced down to the MCU and found that the MEMU record an address in SYS_RAM_UNCERR_ADDR, the address here is exactly where the OS report. However I believe the address in this register shall be the address in RAM. I want to note that address in an constant variable in the MCAL WDG module which we access it very frequently.
So my question is:
What is the significant of the the address in the SYS_RAM_UNCERR_ADDR, especially when it is an adddress in Flash memory?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
hmm, this seems strange. Are you sure that your SW is not writing to this register?

I see no reason why HW would write to it except the multibit ECC fault. Are you seeing the ECC multibit also reported in FCCU NCFS registers?
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
Yes, I am sure that our software is not writing to it.
When this happen, I see that I got the channel 17 of FCCU asserted (MPC5777M). I would note that this does not happen frequently, we saw it may be after a few hours of running software, or not see at at all.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Ok this is strange. Lets skip fault tracking for now and focus on fault conditions.
1. Could you check the whole RAM is correctly initialized after start?
2. Are you doing the test on NXP EVB or on your custom board?
3. Is the core/VDDHVx voltage stable when the issue occurs?
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
1. We have all SRAM and local RAM (IMEM and DMEM) initialized. The SRAM is initialized by IOP, the local ram is initialized by the core it coupled with. FYI, the problem I see always happened detected on the MainCore1.
2. We are working on our ECU.
3. May you described how can I measure the VDDHVx, by the internal ADC channel or the physically pin? FYI, our board have the SBC MC33908 which provides power for the MCU.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
3. May you described how can I measure the VDDHVx, by the internal ADC channel or the physically pin? FYI, our board have the SBC MC33908 which provides power for the MCU.
Use the scope and measure core and supply voltage on the micro pins.
You can find the pin description for your package in datasheet:
2.2.1 Power supply and reference voltage pins/balls
Could you try the SW on the NXPs EVB for reference? To exclude any HW failures.
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
We have some difficulty in reproduce the issue so it take me a while, I can tell that the VDDHV is very stable at 5V and other power supply as well.
Could you try the SW on the NXPs EVB for reference? To exclude any HW failures.
Unfortunately, our project has running for a while then it is not practical to run our software with the EVB (for example: it won't work if some external ASIC is not detected.
Do you have any hint for the meaning of this phenomena? Currently, our software will issue the software destructive reset, is that the correct reaction in this case?
I don't know if this information is helpful, the address recorded in the SYS_RAM_UNCERR_ADDR is of a constant variable storing the base address of the SWT (the WDG driver from NXP's MCAL) , our SWT driver access it very often. We have some different ECU running different application, but the issue point to the same variable I mentioned though they have different address across the ECUs.
Best Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Do you have any hint for the meaning of this phenomena? Currently, our software will issue the software destructive reset, is that the correct reaction in this case?
Issuing the destructive reset on multibit ECC fault is correct. But, it always depend on what the target safety standard demands.
I don't know if this information is helpful, the address recorded in the SYS_RAM_UNCERR_ADDR is of a constant variable storing the base address of the SWT (the WDG driver from NXP's MCAL) , our SWT driver access it very often.
Constant variable -> I believe you mean constant value...
Whole this issue does not make much sense.SYS_RAM_UNCERR_ADDR filled with Flash address.
What happen when you move the data on this address to different address? Does it reports still lthe same address?
What happens when you disable SWT at all?
Is there anything in RGM [FES/DES] when issue happen? Any reset source?
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
If case you are interested, the constant variable is below figure from the MCAL.

As I said, we have multiple different software running, then the memmap will be different for each software, but when the issue happen, though the address in the MEMU is different for different software, we have always trace that address of where the SWT_aBASE_ADDR32 being at.
I think disabling the SWT itself will change the condition of the software since it won't reference to that variable during the SWT servicing. We have tried to review the assembly version of the code where the issue arise but failed to found the issue.
I attach the stack frame of our software where the issue is catched. You can see that our OS rise the Protection log, right after the line 478 of the Wdg_Swt_Trigger, where it is access to the above variable. That seems to me that the MEMU have reported the "relevant" error, but I have no idea how that happens.
Do you think that 3 cores trying to access the same flash portion very frequently may cause the problem, because that address is access by all 3 cores to server their SWT?
Right after the MCU reset, I see that the DES and FES report 0x08 and 0x04 respectively (because we intentionally disable all the FCCU channel to catch only the error that is detected by the OS).

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Do you think that 3 cores trying to access the same flash portion very frequently may cause the problem, because that address is access by all 3 cores to server their SWT?
This depends on the use of resources. If you use SEMA4s correctly, there will be no issue.
And if the access is not granted in time the SWT will just expire and trigger ISR/reset.
MultibitECC is not cause by access issues, but by corruption of data/syndrome on read address.
your DES reports SW destructive reset, this is caused by your SW on some event. What is that?
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am a colleague of @truongtran1 , and I've also been working on this issue. I think we have some updated information to supply, so I hope that we can reengage on this topic. I wanted to supply some additional setup information, which might have not be originally included in @truongtran1 original post, and then I will supply the new information.
Our hardware setup is MPC5777M ED variant in 512BGA package running on our custom ECU, which has been produced/stable for several years at this point. We are running with Lauterbach PowerDebug PRO and PowerTrace II with Aurora trace active, while doing this testing, and we are using the HighTec PowerArchitecture compiler. We have the IOP running at 200MHz, main core 0 and main core 1 running at 300MHz, the fast crossbar running at 200MHz, and we have RWSC=5 and APC=2. Prior to this issue arising, the platform software had been running stably for several years, so we are only experiencing this issue, when we add some additional feature content (enabling main core 1 and full use of SWT). Thus, the AUTOSAR BSW/MCAL is running on the IOP, the customer application is running on main core 0, and just the OS idle task is running on main core 1, which is servicing SWT1 using the NXP MCAL function.
Upon further diagnosis of this issue, I would like to update with the following. When this issue sequence begins, it always begins by main core 1 throwing IVOR1 (machine check exception), and this is followed by either main core 0 or the IOP throwing IVOR6 (program exception) followed immediately by IVOR1. When IVOR6 is thrown on the other core, it is immediately followed by IVOR1 without executing a single instruction of IVOR6, according to the Lauterbach trace. Because main core 1 is the core that always starts the sequence, we've centered our investigation on this core first, which has yielded the following discoveries, which overlap what @truongtran1 reported. We see the following:
- MCAR is set to the flash address where the NXP MCAL WDG data structure is stored to access the SWT registers based on the accessing core.
- MCSR has the LD, MAV, and BUS_DRERR bits set, which matches the fact that a load instruction was being executed from the flash address reported in MCAR.
- Curiously, MEMU reports the error as a System RAM Uncorrectable Error, with a flash address stored in the System RAM Uncorrectable Error register.
- We see no signs of crossbar errors during this time (or at all) using the XBIC module.
The curious thing for us, which is previously pointed out by @truongtran1 , is the fact that a flash address is being written to the System RAM Uncorrectable Error portion of MEMU. I've attached a core register dump of main core 1 to show the IVOR1 related data, and I can confirm the same result previously reported by @truongtran1 , regarding the SYS_RAM_UNCERR_STS and SYS_RAM_UNCERR_ADDR containing a flash address (in our case, the same flash address specified by MCAR).
Relative to the previous set of software that did not produce this issue, the only seemingly relevant changes are:
- SWT peripheral is enabled with SWT2 assigned to IOP, SWT0 assigned to main core 0, and SWT1 assigned to main core 1. All watchdog management is done using the NXP MCAL, using the keyed sequence mode.
- Main core 1 is servicing SWT1 at a rather high rate (every iteration of the OS idle task), since it presently has no other loading.
Other than these items, the system has been stable. Moreover, this ECU has been used to run several different large powertrain configurations in very harsh environments without seeing this issue, so it is not likely for this to be caused by an unstable power supply, especially since we have seen this on all ECUs running this software. We are using NXP MC33908 to supply the core voltage, the Vadc, and the Vio (5.0V in both cases).
We have kind of reached the end of what we can think to do to debug this. Of course, we could start to change some code, but in doing so, we are worried we won't be able to ensure we've resolved the issue, without first root causing the condition that raises it. We are presently running a test, where we have cleared the DECCEN bit of the E2ECTL0 register, just to see if this changes the behavior and the code can run ok, which might be a sign of an error in the end to end ECC system. I would also add that the cores are all executing code in relatively near memory locations to each other, when this sequence tends to occur. Specifically, main core 1 is executing from 256KB Flash Block 3, and the IOP and main core 0 are executing from 256KB Flash Block 2.
Any assistance you can supply in this matter is greatly appreciated, as this seems to be a confusing behavior of the MCU, considering a flash addresses is being stored to the RAM log of MEMU.
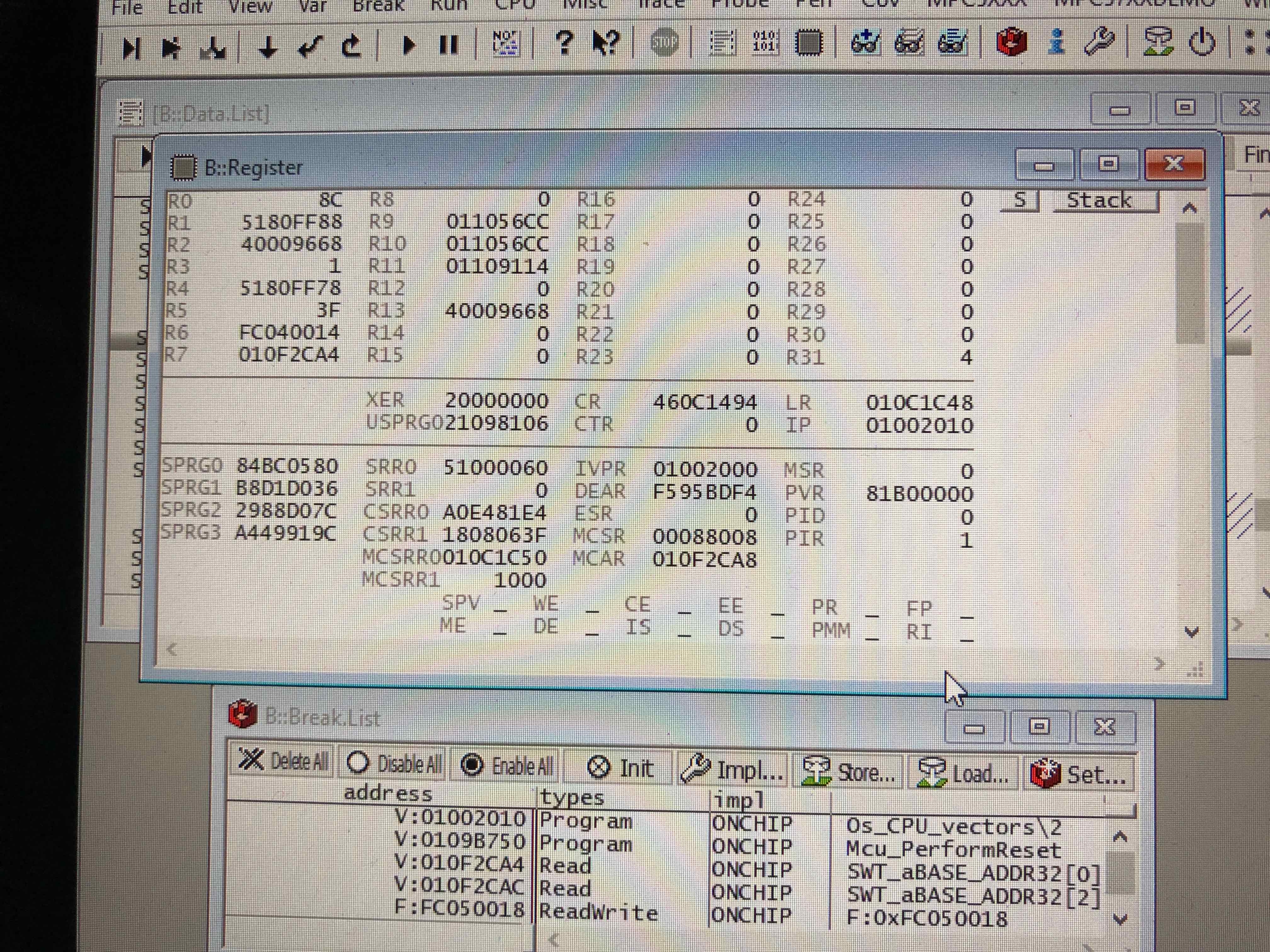{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Thank you for detailed explanation.
From your description it looks like access is not granted to core1 to write to SWT1.
Please check the is MPU is not blocking it when the SWT update is called.
Is this seen on first update, or it happens after some time?
Check AIPS, XBAR, and register protection settings if the core1 has access to the SWT1 registers in that time.
If you have only idle task with no SWT1 function on core1 I guess it runs fine.
How about if you service SWT1 via non-MCAL code from core1? Do you see the issue?
regards,
Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
Thanks for the response, and it's no problem to reply in the community forum instead of the private support ticket, as we only made that just to make sure our request had visibility to NXP. I originally thought that it could be something about MC1 being blocked from accessing SWT1, however, when we check the behavior carefully, I think this might not be the case. In our most recent testing, we actually switched off the end-to-end ECC for all cores (E2ECTL0=0) at the beginning of OS_MAIN(). When we do this, we actually no longer seem to get the exception (IVOR1) on MC1 or MC0. Instead, we get only IVOR6 on MC0, but we do not get this at a consistent address. The only conclusion I can draw from this, when combined with our voltage measurements that I believe show stability, is that there is actually a bad fetching of data occurring from flash, but the data in flash itself has integrity. I say this, because we still get the IVOR6 with an indication of illegal instruction, but we no longer get the machine check indicative of end-to-end ECC error. Because the IVOR1 on MC1 always was a data bus error indication, the MCU must tolerate that, whereas MC0 attempts to execute an instruction, which causes IVOR6.
We will check the items you mentioned, but do you think it is possible that a bad/blocked access from MC1 could somehow snowball to affect the integrity (or appearance of integrity) of instructions executed by MC0? I suppose a scenario could be that MC1 and MC0 both happen to use data that are fetched from the same 256-bit access to flash, which might be buffered in the flash controller.
Parker
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
Since our last correspondence, we performed the following tests:
- Disable SWT1 on main core 1 only and run the code. We can still produce the issue in this configuration.
- Disable SWT on all cores (both main cores and IOP) and run the code. We can still produce the issue in this configuration.
- Analyzed MPU registers at the time of exception (attached), and you can see the MPU is just completely disabled in our system (we don't use MPU feature at this point, nor do we have RTA-OS configured to use it.
At the present time, we are trying to produce the issue in a slightly older version of software, where main core 1 simply boots and sits in an infinite loop. The theory here is that the infinite loop would sit in cache only, so main core 1 would not be hitting the XBAR for RAM or Flash accesses (instruction or data) during run-time. The theory we are working with is that we are only seeing this problem, when both MC0 and MC1 are making regular SRAM/Flash accesses through the XBAR, which might cause some problems. When the issue occurs, we don't see any issues with register protection or XBIC. Are there other configurations we might look for that might be able to cause some problems with MC0 and MC1 sharing the XBAR?
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just wanted to update the thread to supply the measurement of the voltages that you requested. We used a Lauterbach probe to capture the voltage rails at 625ksps synchronous to the execution of the code. The blue line in the attached represents where the exception was raised. The core voltage and 3.3V are obvious from the traces, but in the 5V window, the slightly more noisy signal is the VDD_HV_IO_MAIN, which is supplied by VAUX of MC33908 with ballast transistor. The perfectly flat 5V line is the Vcca with no ballast transistor from MC33908, which is supplying the ADCs of the MCU and serving as an ADC reference. I would also add the following considering this is the 512BGA package:
- VDD_HV_IO_MAIN = 5V
- VDD_HV_IO_JTAG = 3.3V
- VDD_HV_IO_FLEX = 3.3V
- VDD_HV_IO_BD = 3.3V
- VDD_HV_IO_FLEXE = 5.0V
- VDD_HV_IO_EBI = 5.0V
- VDD_HV_FLA uses internal MCU regulator with two external 2.2uF and 1nF caps
In each case, the 3.3V and 5.0V represent the supply voltages shown in the attached.
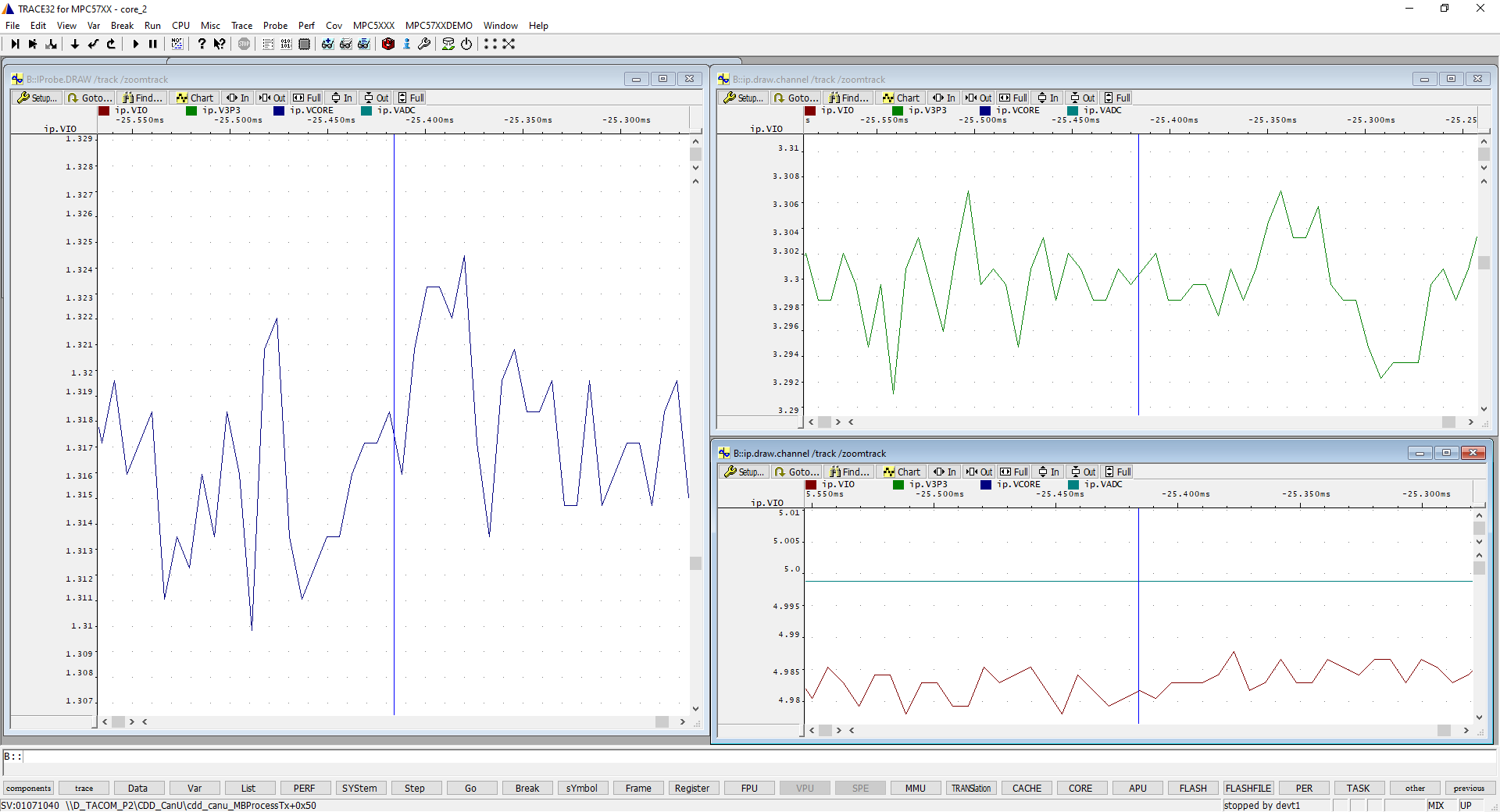{kind=link}