
- Forums
- Product Forums
- General Purpose MicrocontrollersGeneral Purpose Microcontrollers
- i.MX Forumsi.MX Forums
- QorIQ Processing PlatformsQorIQ Processing Platforms
- Identification and SecurityIdentification and Security
- Power ManagementPower Management
- Wireless ConnectivityWireless Connectivity
- RFID / NFCRFID / NFC
- MCX Microcontrollers
- S32G
- S32K
- S32V
- MPC5xxx
- Other NXP Products
- S12 / MagniV Microcontrollers
- Powertrain and Electrification Analog Drivers
- Sensors
- Vybrid Processors
- Digital Signal Controllers
- 8-bit Microcontrollers
- ColdFire/68K Microcontrollers and Processors
- PowerQUICC Processors
- OSBDM and TBDML
- S32M
-
- Solution Forums
- Software Forums
- MCUXpresso Software and ToolsMCUXpresso Software and Tools
- CodeWarriorCodeWarrior
- MQX Software SolutionsMQX Software Solutions
- Model-Based Design Toolbox (MBDT)Model-Based Design Toolbox (MBDT)
- FreeMASTER
- eIQ Machine Learning Software
- Embedded Software and Tools Clinic
- S32 SDK
- S32 Design Studio
- GUI Guider
- Zephyr Project
- Voice Technology
- Application Software Packs
- Secure Provisioning SDK (SPSDK)
- Processor Expert Software
-
- Topics
- Mobile Robotics - Drones and RoversMobile Robotics - Drones and Rovers
- NXP Training ContentNXP Training Content
- University ProgramsUniversity Programs
- Rapid IoT
- NXP Designs
- SafeAssure-Community
- OSS Security & Maintenance
- Using Our Community
-
- Cloud Lab Forums
-
- Knowledge Bases
- ARM Microcontrollers
- i.MX Processors
- Identification and Security
- Model-Based Design Toolbox (MBDT)
- QorIQ Processing Platforms
- S32 Automotive Processing Platform
- Wireless Connectivity
- CodeWarrior
- MCUXpresso Suite of Software and Tools
- MQX Software Solutions
-
- Home
- :
- Product Forums
- :
- PowerQUICC Processors
- :
- Re: T1022: Machine check exception
T1022: Machine check exception
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
T1022: Machine check exception
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We are having a T1022 processor based board , one of the memory mapped device is configured via IFC bus chip select(CS1) using GASIC mode. The memory read/ write to the memory device sometimes leads to kernel throwing exception. I am attaching the T104xRDB.h file in which configuration related to GASIC mode is mentioned , also the kernel exception is as follows-
Machine check in kernel mode.
[169160.053749] Caused by (from MCSR=a000): Load Error Report
[169160.057842] Guarded Load Error Report
[169160.060196] Oops: Machine check, sig: 7 [#3]
[169160.063155] SMP NR_CPUS=8 CoreNet Generic
[169160.065857] Modules linked in: [last unloaded: drv_dwdm]
[169160.069870] CPU: 0 PID: 2873 Comm: util_t10xx-32b Tainted: G D W O 4.1.8-rt8 #1
[169160.076656] task: e817d910 ti: e6214000 task.ti: e6214000
[169160.080745] **bleep**: 10000b54 LR: 10000ad4 CTR: 0fea03a0
[169160.084401] REGS: e6215f10 TRAP: 0204 Tainted: G D W O (4.1.8-rt8)
[169160.090317] MSR: 0002d002 <CE,EE,PR,ME> CR: 28000422 XER: 00000000
[169160.095383] DEAR: b7d363e0 ESR: 00800000
GPR00: 10000ad4 bf9e3be0 b7d3c4c0 00100000 00100000 00000010 00000000 0ffecab0
GPR08: 0ffb71a4 b7d363e0 00100000 0fffffff ffffffff 10019268 10100000 00000000
GPR16: 00000000 100fda04 100fd9f4 10100000 00000000 42222442 10100000 00000000
GPR24: 101115f0 00000000 00000000 0000000f e8220000 0000000f e8220000 bf9e3be0
[169160.126354] **bleep** [10000b54] 0x10000b54
[169160.128705] LR [10000ad4] 0x10000ad4
[169160.130969] Call Trace:
[169160.132106] ---[ end trace 8e582779e7ba09a3 ]---
On some suggestion from NXP community we have done following changes-
1) We have tried both minimum value and maximum value of IFC_CSORn_GPCM[PTO] , still we are facing the same issue. Although on increasing the GPCM[PTO] the frequency of such instances decreases sharply. The GPTO value has been configured at maximum value for all the devices present on IFC bus via GASIC mode.
2)We have referred to the e5500 Core Reference Manual, 4.9.3.1 General Machine Check, Error Report, and NMI Mechanism manual and we found that MCSR[a000] refers to LD and LDG bit.
We are still not able to find the root cause of the problem . Refer to the attached image for description of LD and LDG bits.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
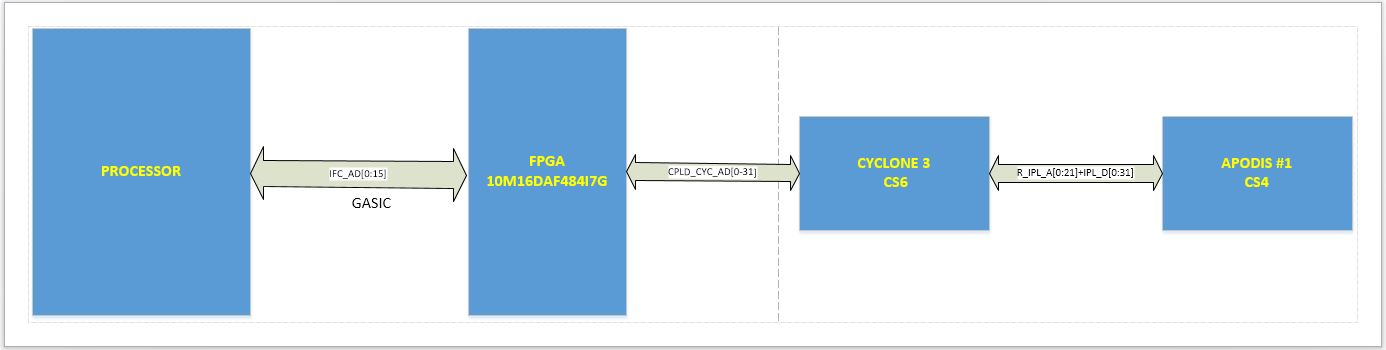
Memory device is APODIS 1 on CS4. We are using FPGA (10M16DAF484I7)? and CYCLONE 3 as glue logic to generate timing for APODIS1 on CS4.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Kernel exceptions are through during write or read? From the previous communication from customer "The read/write instruction to the respective interface is not continuous . We are fetching performance and alarms related data from the respective interface in a time interval of 1 minute." It seems that kernel exception is during reading only. Is it correct?
- From the block diagram it seems that processor is generating IFC transaction to FPGA and then FPGA is sending it to CYCLONE FPGA and then cyclone is sending commands to memory. Is this understanding correct? From the schematic it seems that all the chip select is connected FPGA, do all the chip select are in use and error is occuring while accessing with one specific chip select?
- please provide register dump after and before errror.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@yipingwang Please find response to queries raised-
1) Kernel exceptions are through during write or read? From the previous communication from customer "The read/write instruction to the respective interface is not continuous . We are fetching performance and alarms related data from the respective interface in a time interval of 1 minute." It seems that kernel exception is during reading only. Is it correct?
We are running polling application which reads alarms and performance data during which this error occurs i.e. read transaction only. During configuration of the device write transactions are also involved and there is no error there. So seems to be an issue with read only.
2)From the block diagram it seems that processor is generating IFC transaction to FPGA and then FPGA is sending it to CYCLONE FPGA and then cyclone is sending commands to memory. Is this understanding correct?
Yes
From the schematic it seems that all the chip select is connected FPGA, do all the chip select are in use and error is occuring while accessing with one specific chip select?
Yes all chip selects are in use and we are facing issue in accessing CS4.
3) please provide register dump after and before error.
Could you please provide the details of registers to be read before and after the error.
Register dump after kernel panic attached in the same thread (also attached for reference)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You said that you are facing issue while reading and you are reading data in polling mode path from IFC controller to memory is long (means through two FPGA)
I am expecting if you can share IFC controller dump before and after kernel crash
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@yipingwangAttached is the IFC controller complete dump from 0xfe124000 - 0xfe125440 before and after machine check issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
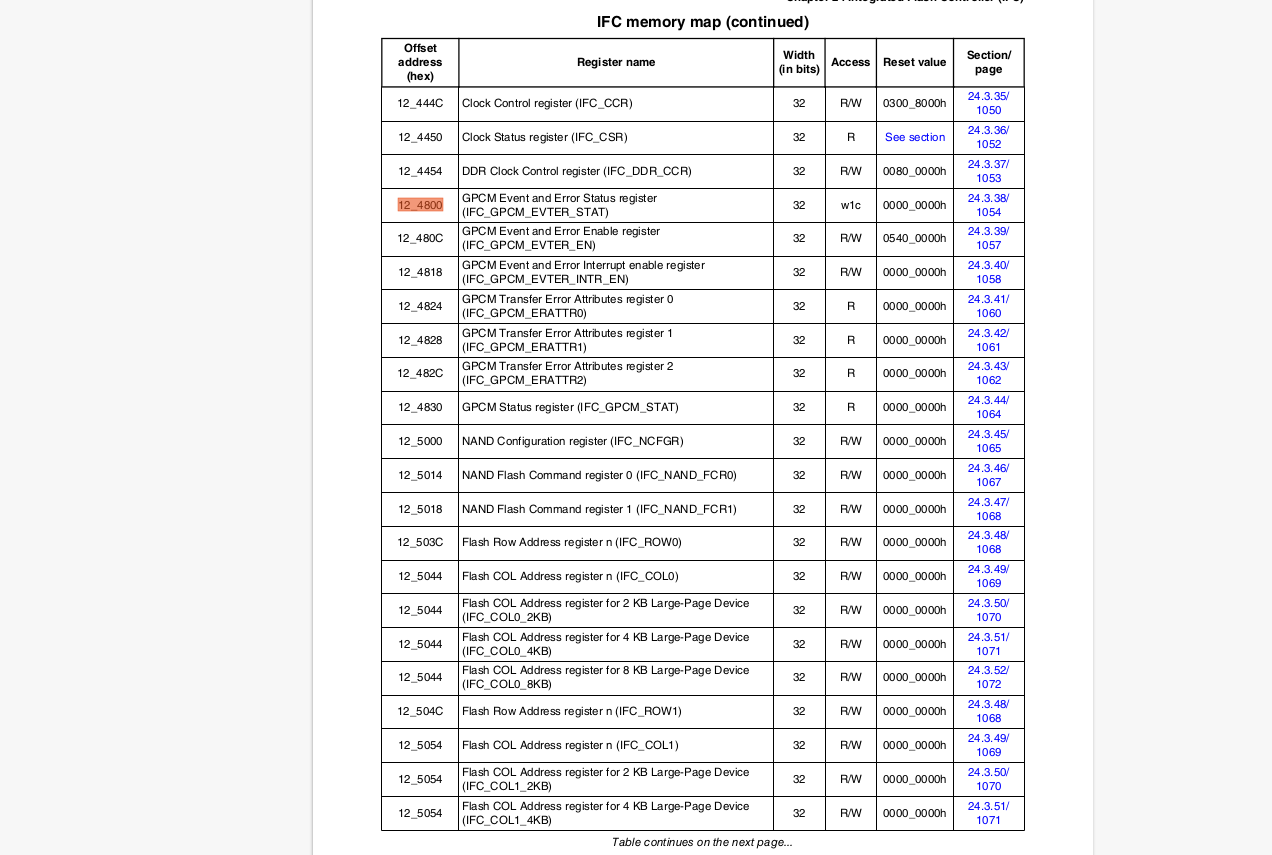
Thanks for sharing IFC controller dump. But it seems that dump is not complete, GPCM event and error register (offset 12_5800 is missing.
Please share complete dump till register 12_5830
Few suggestion:
- GPTO value is not not set to max value, Please try with maximum value.
- Reduce IFC clock speed from IFC_CCR register and then try.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@yipingwang As per the reference manual available with us, GPCM event and error register is at offset 12_4800 . We are referring to QorIQ T1040 Reference Manual (screenshot of front page is attached).
IFC Registers dump till 12_5830 is also attached.
Regarding your suggestion:
- GPTO value is not not set to max value, Please try with maximum value.
As i have already conveyed with GPTO set to maximum value the frequency of machine check is less and when GPTO value is set to minimum value machine check is observed frequently, so to debug the issue we have intentionally set GPTO to 1 in our test setup.
2. Reduce IFC clock speed from IFC_CCR register and then try.
According to the end point device clock requirement , the current IFC clock speed[divide by 8] is minimum which we can set for the proper working of the end point device.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please refer latest RM from NXP web "QorIQ T1040 Reference Manual, Rev. 2, 06/2020"
IFC configure as follows.
(IFC_CSORn_GPCM) ABRT_RSP_EN =1, RGETA =0 Abort mode. IFCTA_B signal acts as abort signal
Before machine check error:
0xfe125800 :: 0x01000000 (Parity Error but no time out error)
After machine check error:
0xfe125800 :: 0x05000000 (Parity and time out error)
This means IFC controller requested for data but before data is recieved time out event occurs and lead to system crash.
In customer design data is coming from memory>> 2-FPGA >> IFC controller. Hence path is long enough. So it is recommended to either reduce frequency of operation (which is not possible due to memory limitation) or increase the dealy time (GPTO)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
IFC configure as follows.
(IFC_CSORn_GPCM) ABRT_RSP_EN =1, RGETA =0 Abort mode. IFCTA_B signal acts as abort signal
We have configured IFC CS in GASIC mode, is the above mentioned configuration valid for GASIC? As per latest datasheet the above configuration is valid only for GPCM mode.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry for creating confusion.
It is true that RGETA bit is not related to GPCM mode.
Please refer section 24.7.2.2 Generic ASIC read data Sampling.
It mention that "The assertion of RDY_B indicates the start of read data phase. In the case the device has not asserted RDY_B before timeout occurs, the host terminates the transfer by deasserting the CS_B."
My understanding is that RDY_B signal is not asserted before timeout in your case.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
We are trying to emulate the scenario in which machine check error occurs because of timeout. Will keep you posted on these observations
However , on further debugging we found that parity check is bypassed in IFC_CSORn_GPCM. In case we enable the parity using bit 2 i.e. PAR_EN , we are seeing machine check error on every cycle. We intend to enable parity check in the final release. Please suggest how it is to be handled by Processor in case there is a parity fault. Attached fault log
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When parity check is enable: (section 24.7.2)
During Write:
Host controller wait (CSORn[GAPERRD] time) for parity error enable signal before de-asserting chip select.
What is the value set for CSORn[GAPERRD]? Can you try with maximum value?
As per the scenario and results now probability of error increase due to waiting time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
(CSORn[GAPERRD] is set to 00 i.e. 1 IFC_CLK cycle. We are checking the logic for parity again. Will try with highest value i.e. 4 subsequently.
I have another question. As per CSORn[PAR_EN] =0 , parity checking was disabled , still machine check error dump gave error because of parity error. Any reason for that ??
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please detail how you conclude that machine check error is due to parity error only and not for time out?
What it the status of PERR_B signal when parity error occurred
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
IFC controller don't have such settings.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please find attached block diagram and corresponding schematic.
We are using MAX10 (10M16DA) and Cyclone 3 FPGA to generate timing for target APODIS device. IFC_RB1_N is generated by MAX10 for processor.
Software team is running continuous read/write instruction and will update.
Please advise
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please share schematic of interface, datasheet of interfaced device.
Do you run continuous read/write instruction on the respective interface to check if issue still present?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@yipingwangthe schematic of the interface is shared by Hardware team[Kashish Anand] in this thread.
Do you run continuous read/write instruction on the respective interface to check if issue still present?
The read/write instruction to the respective interface is not continuous . We are fetching performance and alarms related data from the respective interface in a time interval of 1 minute.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You said "We are having a T1022 processor based board , one of the memory mapped device is configured via IFC bus chip select(CS1) using GASIC mode. The memory read/ write to the memory device sometimes leads to kernel throwing exception."
Here memory device is FPGA (10M16DAF484I7)?