
- Forums
- Product Forums
- General Purpose MicrocontrollersGeneral Purpose Microcontrollers
- i.MX Forumsi.MX Forums
- QorIQ Processing PlatformsQorIQ Processing Platforms
- Identification and SecurityIdentification and Security
- Power ManagementPower Management
- Wireless ConnectivityWireless Connectivity
- RFID / NFCRFID / NFC
- Advanced AnalogAdvanced Analog
- MCX Microcontrollers
- S32G
- S32K
- S32V
- MPC5xxx
- Other NXP Products
- S12 / MagniV Microcontrollers
- Powertrain and Electrification Analog Drivers
- Sensors
- Vybrid Processors
- Digital Signal Controllers
- 8-bit Microcontrollers
- ColdFire/68K Microcontrollers and Processors
- PowerQUICC Processors
- OSBDM and TBDML
- S32M
- S32Z/E
-
- Solution Forums
- Software Forums
- MCUXpresso Software and ToolsMCUXpresso Software and Tools
- CodeWarriorCodeWarrior
- MQX Software SolutionsMQX Software Solutions
- Model-Based Design Toolbox (MBDT)Model-Based Design Toolbox (MBDT)
- FreeMASTER
- eIQ Machine Learning Software
- Embedded Software and Tools Clinic
- S32 SDK
- S32 Design Studio
- GUI Guider
- Zephyr Project
- Voice Technology
- Application Software Packs
- Secure Provisioning SDK (SPSDK)
- Processor Expert Software
- Generative AI & LLMs
-
- Topics
- Mobile Robotics - Drones and RoversMobile Robotics - Drones and Rovers
- NXP Training ContentNXP Training Content
- University ProgramsUniversity Programs
- Rapid IoT
- NXP Designs
- SafeAssure-Community
- OSS Security & Maintenance
- Using Our Community
-
- Cloud Lab Forums
-
- Knowledge Bases
- ARM Microcontrollers
- i.MX Processors
- Identification and Security
- Model-Based Design Toolbox (MBDT)
- QorIQ Processing Platforms
- S32 Automotive Processing Platform
- Wireless Connectivity
- CodeWarrior
- MCUXpresso Suite of Software and Tools
- MQX Software Solutions
- RFID / NFC
- Advanced Analog
-
- NXP Tech Blogs
- Home
- :
- i.MX Forums
- :
- i.MX Processors
- :
- Yolov5 tflite deployment on NPU - IMX8MP evk
Yolov5 tflite deployment on NPU - IMX8MP evk
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have trained yolov5 with VisDrone dataset in PyTorch. To run the model on IMX8MP-evk, it need to be converted to 8-bit(int8/uint8). Used eIQ Portal to quantize and convert to tflite format. Steps in conversion are as follows: best.pt -> best.onxx -> best.tflite (Input:uint8, model(filter:int8/bias:int32), Output: float32, screenshot attached: tflite-model.JPG). Per channel quantization is used.
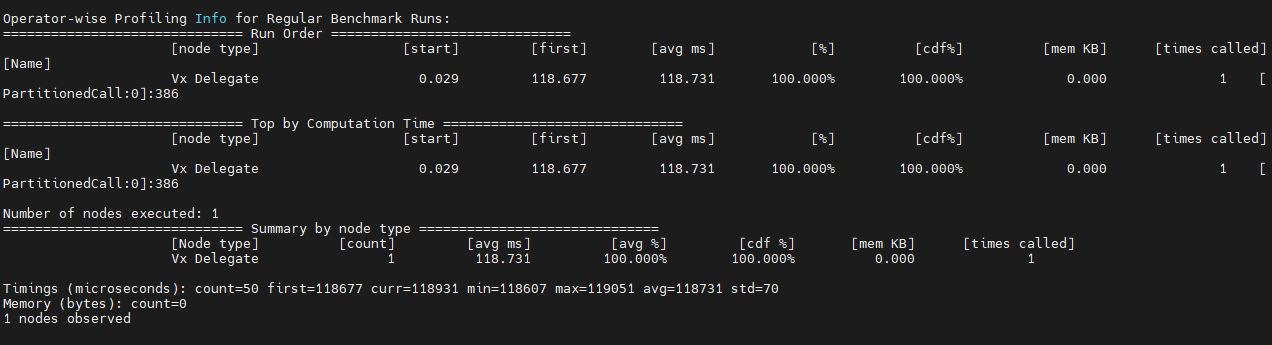
Benchmarking: ./benchmark_model --graph=/path2model/best_uint8_int8_float.tflite --external_delegate_path=/usr/lib/libvx_delegate.so --enable_op_profiling=true --max_delegated_partitions=10000 (screenshot attached: benchmark_1.JPG, benchmark_2.JPG, benchmark_3.JPG)
Object Detection:
gstreamer pipeline is used to test above quantized model on webcam. Executing the pipeline on CPU/NPU results in error (screenshot attached: error_pipeline.JPG).
Converting to float32_float32_float32.tflite didn't work as well.
Tensor format should be NCHW for TF-Lite, is the input and output shape correct ?
Need help in creating a working pipeline, C++ code would be best
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
The default input model should be filled in with the shape from the original model, take a look at the eIQ link for more information on quantization.
https://community.nxp.com/t5/eIQ-Machine-Learning-Software/tkb-p/eiq@tkb
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, after changing the input shape it works fine.
How can we find performance on NPU or calculate detection time per frame ? Executing gst-launch with [ GST_DEBUG="GST_TRACER:7" GST_TRACERS="framerate"] indicates FPS of 6 to 9 which is for the complete pipeline not per frame. Is that a correct indication or is there a different way to calculate detection time per frame ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you checked this notes : i.MX8MP NPU debug and fine tune application note - NXP Community .
Let me know for more details on this topic.
Thanks !!!
sams4
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
The default input model should be filled in with the shape from the original model, take a look at the eIQ link for more information on quantization.
https://community.nxp.com/t5/eIQ-Machine-Learning-Software/tkb-p/eiq@tkb
Regards