
- Forums
- Product Forums
- General Purpose MicrocontrollersGeneral Purpose Microcontrollers
- i.MX Forumsi.MX Forums
- QorIQ Processing PlatformsQorIQ Processing Platforms
- Identification and SecurityIdentification and Security
- Power ManagementPower Management
- Wireless ConnectivityWireless Connectivity
- RFID / NFCRFID / NFC
- Advanced AnalogAdvanced Analog
- Neural Processing UnitsNeural Processing Units
- MCX Microcontrollers
- S32G
- S32K
- S32V
- MPC5xxx
- Other NXP Products
- S12 / MagniV Microcontrollers
- Powertrain and Electrification Analog Drivers
- Sensors
- Vybrid Processors
- Digital Signal Controllers
- 8-bit Microcontrollers
- ColdFire/68K Microcontrollers and Processors
- PowerQUICC Processors
- OSBDM and TBDML
- S32M
- S32Z/E
-
- Solution Forums
- Software Forums
- MCUXpresso Software and ToolsMCUXpresso Software and Tools
- CodeWarriorCodeWarrior
- MQX Software SolutionsMQX Software Solutions
- Model-Based Design Toolbox (MBDT)Model-Based Design Toolbox (MBDT)
- FreeMASTER
- eIQ Machine Learning Software
- Embedded Software and Tools Clinic
- S32 SDK
- S32 Design Studio
- GUI Guider
- Zephyr Project
- Voice Technology
- Application Software Packs
- Secure Provisioning SDK (SPSDK)
- Processor Expert Software
- Generative AI & LLMs
-
- Topics
- Mobile Robotics - Drones and RoversMobile Robotics - Drones and Rovers
- NXP Training ContentNXP Training Content
- University ProgramsUniversity Programs
- Rapid IoT
- NXP Designs
- SafeAssure-Community
- OSS Security & Maintenance
- Using Our Community
-
- Cloud Lab Forums
-
- Knowledge Bases
- ARM Microcontrollers
- i.MX Processors
- Identification and Security
- Model-Based Design Toolbox (MBDT)
- QorIQ Processing Platforms
- S32 Automotive Processing Platform
- Wireless Connectivity
- CodeWarrior
- MCUXpresso Suite of Software and Tools
- MQX Software Solutions
- RFID / NFC
- Advanced Analog
- Neural Processing Units
-
- NXP Tech Blogs
- Home
- :
- QorIQ Processing Platforms
- :
- T-Series
- :
- T2080RDB cpu core hang problem
T2080RDB cpu core hang problem
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
T2080RDB cpu core hang problem
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello everyone,
We have hang problem in a scenario based on ipsec esp null with a custom board based on T2080 SoC with SDK 1.6.
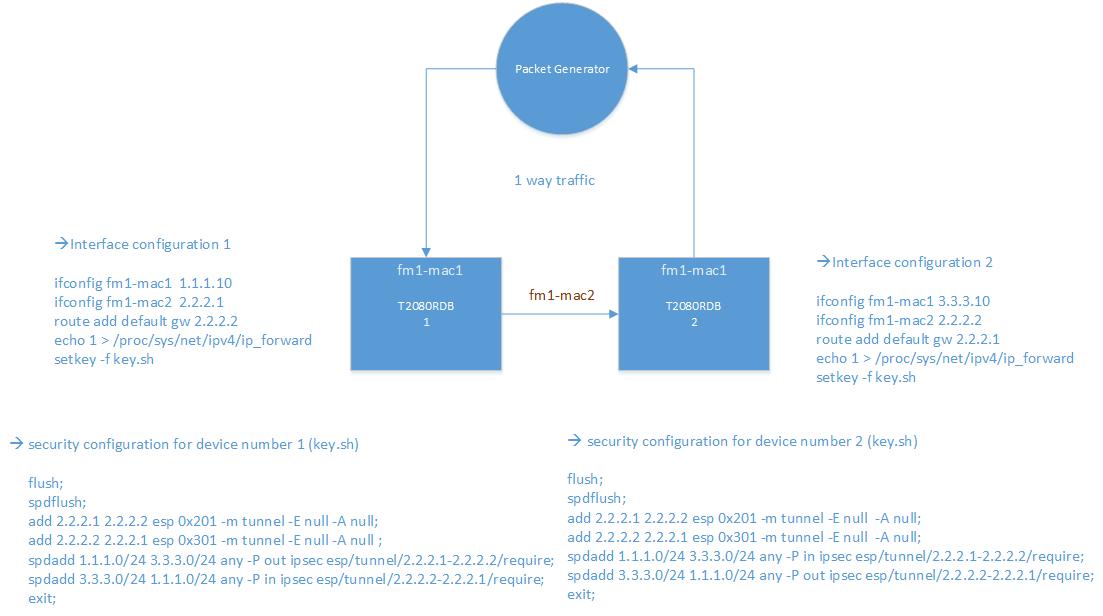
We are using a packet generator (IXIA) and generate internet mix packets for testing. The test setup and device configurations is depicted on the attached image.
Approximately after 10 hours some of the cpu cores are hanging while others are still processing packets. After enabling soft lock up detection in kernel we got cpu stuck messages on the console. But since some cores are hanged, the console is also locked.
Then we repeated the same scenario with the reference boards NXP T2080RDB. Strangely we got the same problem, after 10-12 hours some cores are hanged while others are still processing packets. We used the SDK 1.6 images which are downloaded from NXP official site. (Kernel,dtb,ramdisk, rcw). And our fman microcode version is 108.4.5.
Then we switched to SKD 2.0 on T2080RDB boards and did the same network tests, fortunately we didnt got any problem. Approximately for 3-4 days it worked without any problem. We also used the official binaries form SDK 2.0 and fman microcode version is still 108.4.5
We didnt understand why some cores in T2080RDB are hanging if we use SDK 1.6 instead of SDK 2.0.
We also did same tests on T4240RDBs. In these test there is no problem either using SDK1.6 or SDK2.0.
It will be very hard for us to switch from SDK 1.6 kernel to SDK 2.0, we have lots of customizations in SDK 1.6.
So could you please help us about finding the problem in SDK 1.6, maybe there are errates, bug fixes done in SDK 2.0.
We have critical changes in SDK 1.6 kernel so it is not an easy task to switch to new sdk like SDK 2.0.
Any help will be appreciated.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tested it for a few days and found it could be (EMI)electromagnetic interference (in-board or inter-board) or voltage. The SDK I used was V1.9, not 2.0. If there is not a problem with the 2.0 SDK, it is probably a software problem.
Test method: input raw IP traffic to device by spirent what make CPU soft interrupt more than 90% , about three hours to stop the traffic ,problem can appear.(rcu CPU stall)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Yiping Wang;
The attached fman microcode is same with the fman from sdk 1.6. The md5sum of fman from sdk 1.6 is same with the md5sum of the attached fman microcode.
We already used this fman while testing with sdk 1.6.
And also one of my friend started the sdk 1.6 test with the atatched fman , for a while one of the core is hang and console is locked with the messsage "INFO:rcu_sched self-detected stall on CPU{x}.
We recognized that if we control the rate of the incoming traffic to make sure that the cpus are not overloaded too much, the problem is disappearing. If we can succeed to make a rate control from ingress and drop the packets in case of overloading situations we may apply this solution.
But we prefer to not to solve this problem with rate control, I hope there is a fix in community maintained SDK's which have greater version than SDK 2.0.
Thank you very much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have the same problem as you. How did you finally settle it
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you use SDK 2.0 1703 release? I found this known issue in SDK 2.0 1703 document.

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to modify bout what"Two patches addressing the RCU stall issue were backported from kernel version v4.6". thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thank you very much for your response.
I also tried nohz=off but nothing has changed, I got "the rce_sched self-detected stall on CPU{x}" message , and then the console is locked , but some cores are still alive and processing the packets.
We did the same tests by using T4240RDB board but there is no problem with T4240.
Maybe this is a problem of Linux operating system and in since there are more cores in T4240 than T2080 the problem is still exist but we could not succeed to create the problem in T4240. Maybe trying the latest linux kernels like 4.20 , 5.x will solve the problem.
The bad scenario for us is we are using T2080 in our custom board and we also get the same error. Finding the error cause by using T2080rdb is easier than finding in custom board, so we are using t2080rdb board in our tests.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello ömer faruk er,
Please use the attached FMAN ucode fsl_fman_ucode_t2080_r1.0_106_4_14.bin and SDK 1.6.
Thanks,
Yiping
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Yiping,
Do you have any other suggestion about the above problem of T2080rdb with SDK 2.0 ?
Thank you very much
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Yiping,
In my previous post I told that the hang problem was disappeared by using SDK 1.9.
Unfortunately after 3 days testing with ESP NULL operation which cause high softirq rate and make all the cpus %0 idle , we recreated the error case.
The serial console is locked, some of the cores are still processing packets while some of them are %100 idle but could not process packets. The overall performance is dropped from 5.7 Gbps to 3.9Gbps.
And at the console output the printed dump about the error is "rcu_sched detected stalls on CPU ..."
All the kernel,dtb,fman microcode , file system are extracted from SDK 1.9 .
Do we have to try SDK 2.0 or is there any another solution in SDK 1.9 , like changing the kernel config to give cpu time to low priority tasks while there are heavy load of soft irq.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Idle CPU that is not receiving scheduling-clock interrupts is said to be "dyntick-idle".
The CONFIG_NO_HZ_IDLE=y Kconfig option causes the kernel to avoid sending scheduling-clock interrupts to idle CPUs, which is
critically important both to battery-powered devices and to highly virtualized mainframes.
Therefore, system with aggressive real-time response constraints often run CONFIG_HZ_PERIODIC=y kernels(or CONFIG_NO_HZ=n) in order to avoid degrading from-idle transition latencies.
This boot parameter "nohz=" that can be used to disable dyntick-idle mode in CONFIG_NO_HZ_IDLE=y kernel by specifying "nohz=off".
By the default, the system boot with "nohz=on", enabling dyntick-idle mode.
Please specify "nohz=off" to disable dyntick-idle.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
commit dc4be41bb05fcc690ddabac747d3e6d6d0952c8a
Author: Scott Wood <[email protected]>
Date: Wed Apr 16 17:28:14 2014 -0500
iommu/fsl: Work around erratum A-007907
Erratum A-007907 can cause a core hang under certain circumstances.
Part of the workaround involves not stashing to L1 Cache. On affected
chips, stash to L2 when L1 is requested.
Signed-off-by: Varun Sethi <[email protected]>
Signed-off-by: Scott Wood <[email protected]>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please check whether this problem still remains when using the attached uImage from QorIQ SDK 1.9 release.
If this problem doesn't exist, please refer to the following patches.
e5b01f1348e90e86b9f6abadc842005f77085caa
bcd586241449dc177a82069117e41e7be90683bd
4c642e7af5e9e605b9fb6b8130216548c7bc180b
18b0779a47ba765a5f02113450ef5f1d7c4f9acb
300c3ff86988bc13e310b58d9c7c786528697150
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your answer. I've tested with last uImage you sent; there is no problem with this uImage. Where can I find these patches that you listed to apply SDK1.6 kernel ?
Thanks & Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello ömer faruk er,
Please check whether the attached patches related with this issue.
You could download and install QorIQ SDK 1.9 source ISO, which could be downloaded from Linux® SDK for QorIQ® Processors | NXP .
Then run "bitbake virtual/kernel -c patch -f", you will get Kernel source in build_t2080rdb/tmp/work/t2080rdb-fsl-linux/linux-qoriq/4.1-r0/git.
Please run "git log" to review all patches after June 19th 2015.
Thanks,
Yiping
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your answers. I tried with your uImage on the same test scenario, problem continues. Is there anything other than this errata to solve this problem ?
Thanks